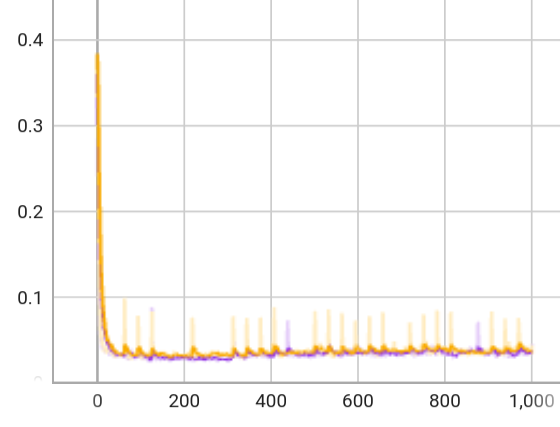
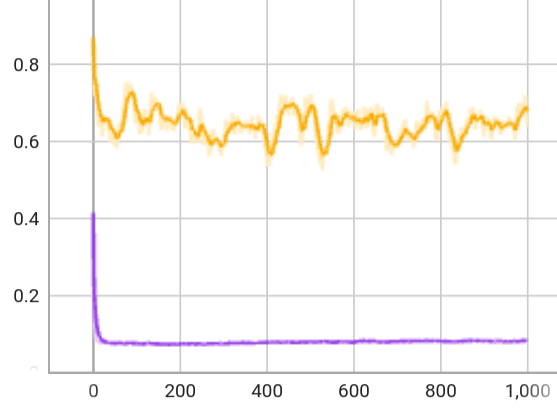
Methodology
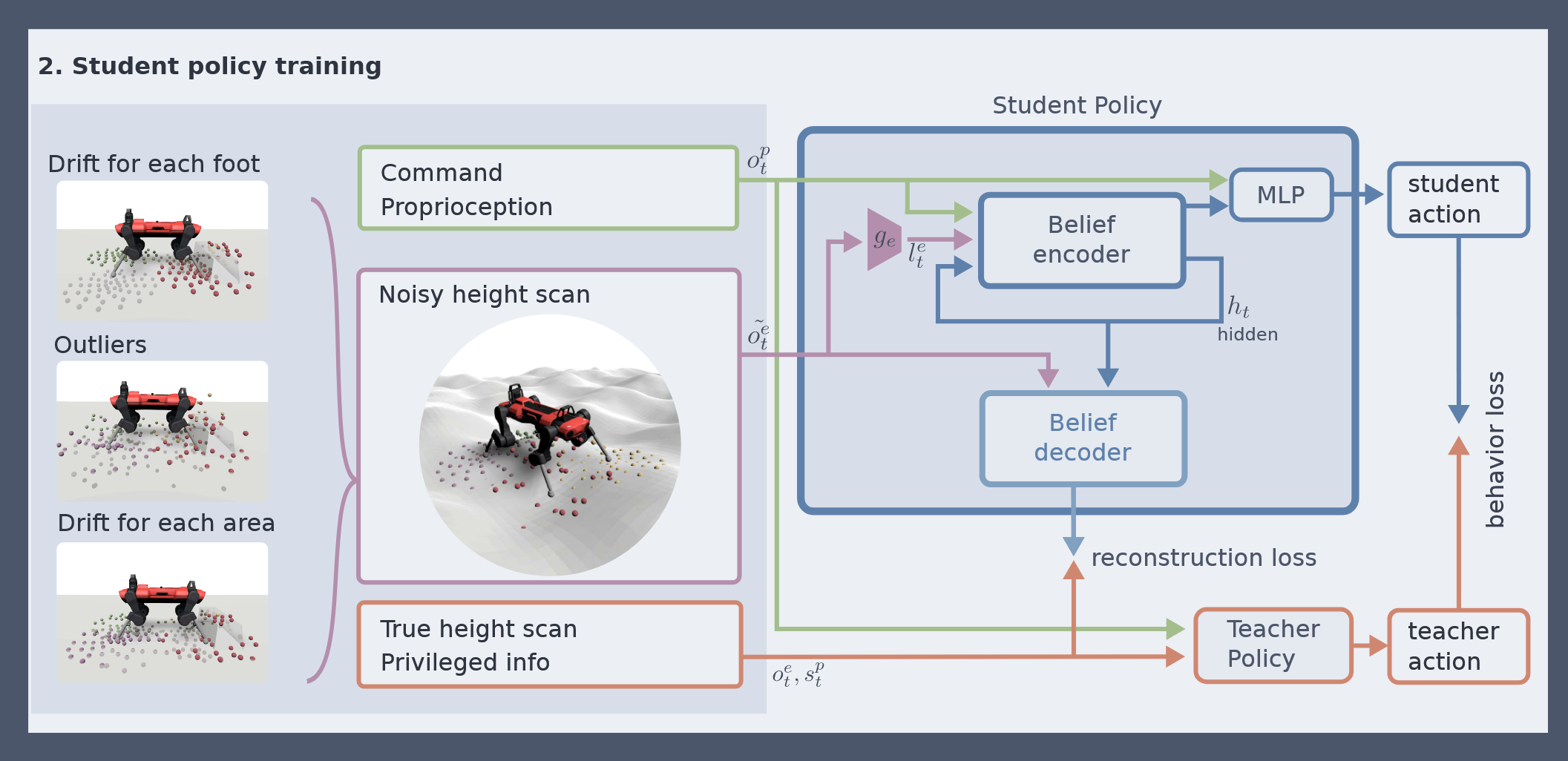
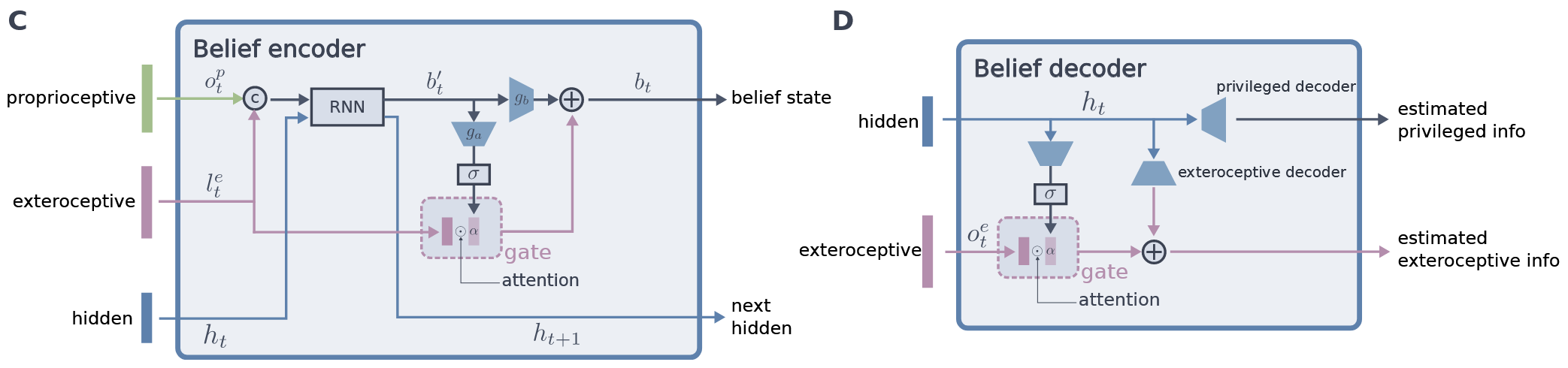
The key component is a recurrent encoder that combines proprioception and exteroception into an integrated belief state. The encoder is trained in simulation to capture ground-truth information about the terrain given exteroceptive observations that may be incomplete, biased, and noisy. The belief state encoder is trained end-to-end to integrate proprioceptive and exteroceptive data without resorting to heuristics. It learns to take advantage of the foresight afforded by exteroception to plan footholds and accelerate locomotion when exteroception is reliable, and can seamlessly fall back to robust proprioceptive locomotion when needed.
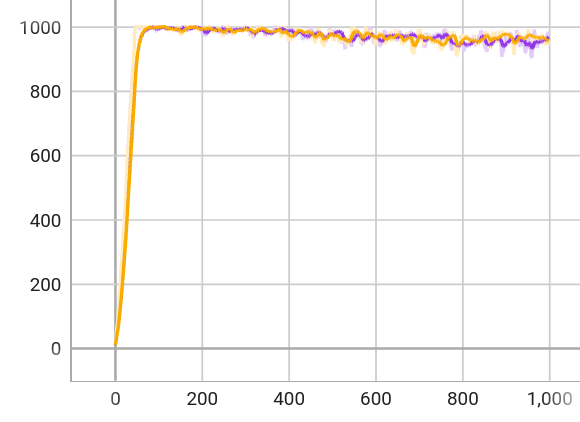
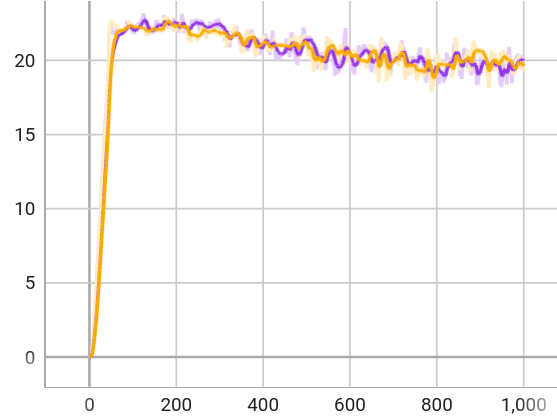
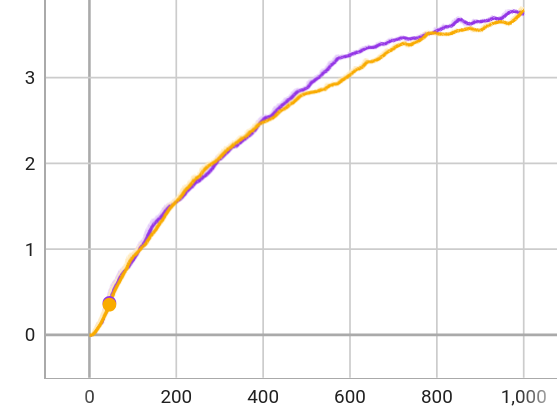
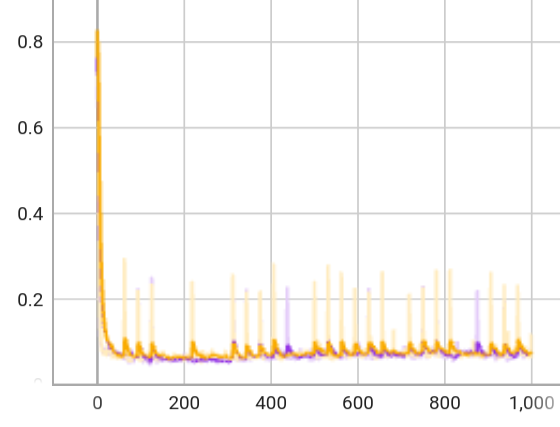
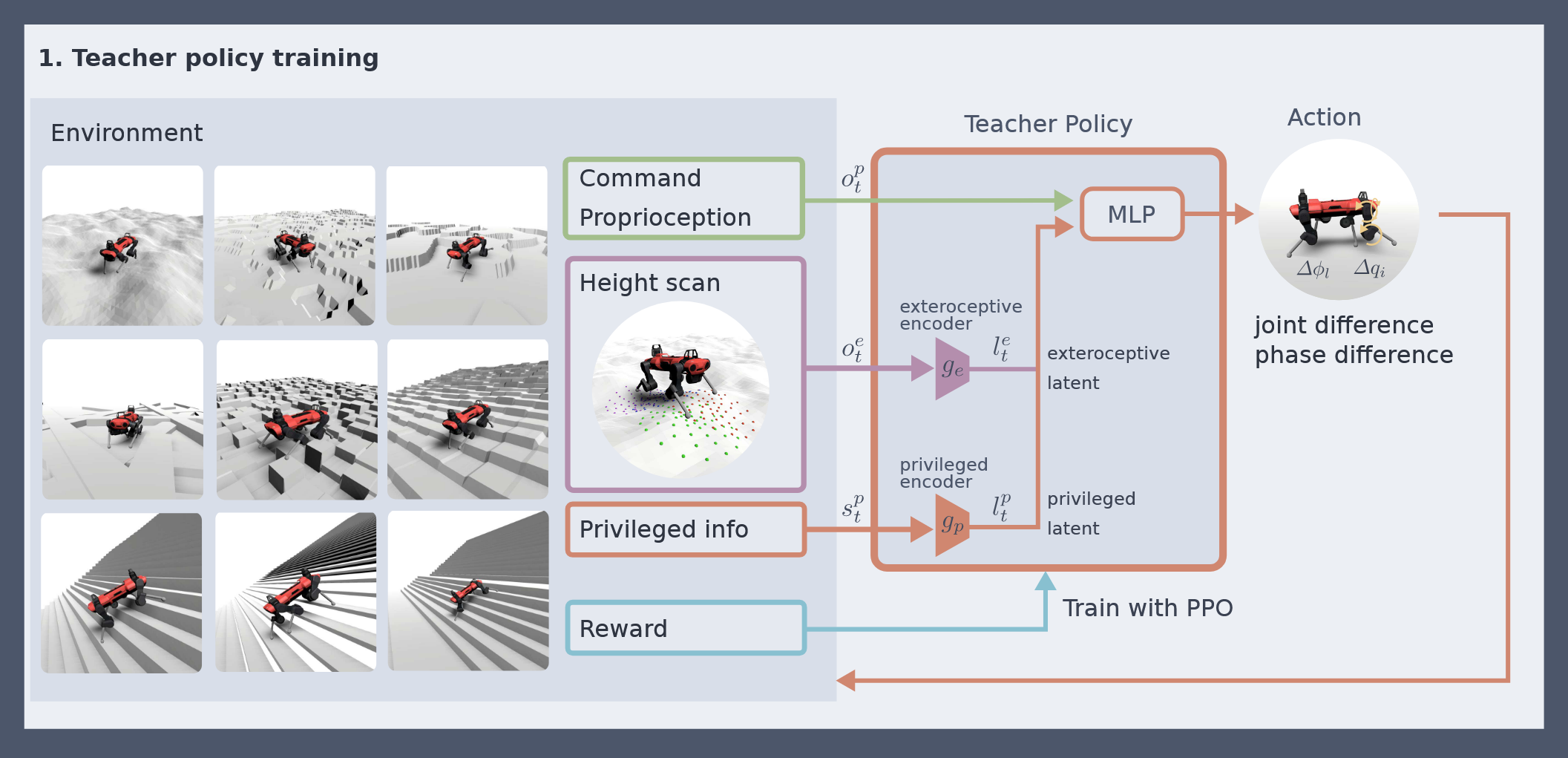
The controller is trained via privileged learning. A teacher policy is first trained via Reinforcement Learning (RL) with full access to privileged information in the form of the ground-truth state of the environment. This privileged training enables the teacher policy to discover the optimal behavior given perfect knowledge of the terrain. We then train a student policy that only has access to information that is available in the field on the physical robot. The student policy is built around our belief state encoder and trained via imitation learning. The student policy learns to predict the teacher's optimal action given only partial and noisy observations of the environment.
Policy Architecture
Noise Model
Two different types of measurement noise are applied when sampling the heights:
- Shifting scan points laterally.
- Perturbing the height values.
- per scan point
- per foot
- per episode
- Nominal noise assuming good map quality during regular operation.
- Large offsets through high per-foot noise to simulate map offsets due to pose estimation drift or deformable terrain.
- Large noise magnitude for each scan point to simulate complete lack of terrain information due to occlusion or mapping failure.
.png)